


Data can make a story. It can be the backbone of an investigation, and it can lead to new insights and new ways of thinking. Unfortunately, the data you want isn’t always readily available. It’s often on the web, but it isn’t always packaged up and available for download. In cases like these, you might want to leverage a technique called web scraping to programmatically gather the data for you.
There are many ways to scrape, many programming languages in which to do it and many tools that can aid with it. (See the Data Journalism Handbook for more.) But here we’ll go through how to use the language Python to perform this task. This will give you a strong sense of the basics and insights into how web pages work. It will challenge you a bit to think about how data is structured.
We recommend that you download the Anaconda Python distribution and take a tutorial in the basics of the language. If you have no familiarity whatsoever, Codecademy can get you started.
In this tip sheet we’ll be using the Polk County [Iowa] Current Inmate Listing site as an example. From this site, using a Python script, we’ll extract a list of inmates, and for each inmate we’ll get some data like race and city of residence. (The entire script we’ll walk through is open and stored here at GitHub, the most popular online platform for sharing computer code. The code has lots of commentary to help you.)
A web browser is the first tool you should reach for when scraping a website. Most browsers provide a set of HTML inspection tools that help you lift the engine-bay hatch and get a feel for how the page is structured. Access to these tools varies by browser, but the View Page Source option is a mainstay and is usually available when you right click directly on a page.
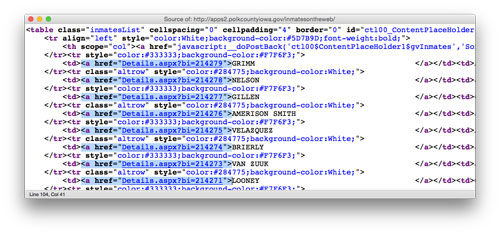
(Page source of the Polk County Current Inmate Listing page)
When viewing a page’s HTML source, you’re looking for patterns in the arrangement of your desired data. You want your values to predictably appear in rows in a <table> or in a set of <div>, <p>, or other common elements. In our example we see that links to inmate details, <a href=”Details.aspx?…”>, are neatly listed in table rows. This will make for easy scraping.
Now that we have a rough idea of how our values are arranged in the HTML, let’s write a script that will extract them. We’ll rely on two common Python packages to do the heavy lifting, Requests and Beautiful Soup. Both of these packages are so popular that you might already have them installed; if not, install them before you run the code below.
At a high level, our web scraping script does three things: (1) Load the inmate listing page and extract the links to the inmate detail pages; (2) Load each inmate detail page and extract inmate data; (3) Print extracted inmate data and aggregate on race and city of residence.
Let’s start coding.
We’ll set ourselves up for success by importing requests and BeautifulSoup at the top of our script.
Our first chunk of logic loads the HTML of the inmate listing page using requests.get(url_to_scrape) and then parses it using BeautifulSoup(r.text). Once the HTML is parsed, we loop through each row of the inmatesList table and extract the link to the inmate details page. We don’t do anything with our link yet, we just add it to a list, inmates_links.
We now loop through each inmate detail link in our inmates_links list, and for each one we load its HTML and parse it using the same Requests and BeautifulSoup methods we used previously. Once the inmate details page is parsed, we extract the age, race, sex, name, booking time and city values to a dictionary.
BeautifulSoup’s select and findAll methods did the hard work for us — we just told it where to look in our HTML (using our browser inspection tools above). Each inmate gets a dictionary and all the dictionaries get appended to an inmates list.
We’ve ended up with a list, inmates_links, that contains all of the values. We can print those out, but let’s first do some aggregation by looping over the city and races values.
Our printed output looks like this in our terminal:
As you can see, the logic to load and parse the HTML is simple thanks to Requests and Beautiful Soup. Most of the effort in web scraping is digging through the HTML source in your browser and figuring out how the data values are arranged. Start simple — just grab one value and print it out. Once you figure out how to extract one value, you’ll often be very close to the rest of the data. One note of caution, though: It’s pretty easy to flood a web server with requests when you’re scraping. If you’re looping through a bunch of links that go to one website, it’s polite to wait a second between each request.
The full web scraping example script is available and has been commented on heavily. Copy it. Paste it. Run it. Edit to fit your needs.
Should the Polk County Inmates site change or become unavailable, you can find an archived copy of the inmates list page at http://perma.cc/2HZR-N38X and an example of an inmate detail page at http://perma.cc/RTU7-57DL.
Expert Commentary