



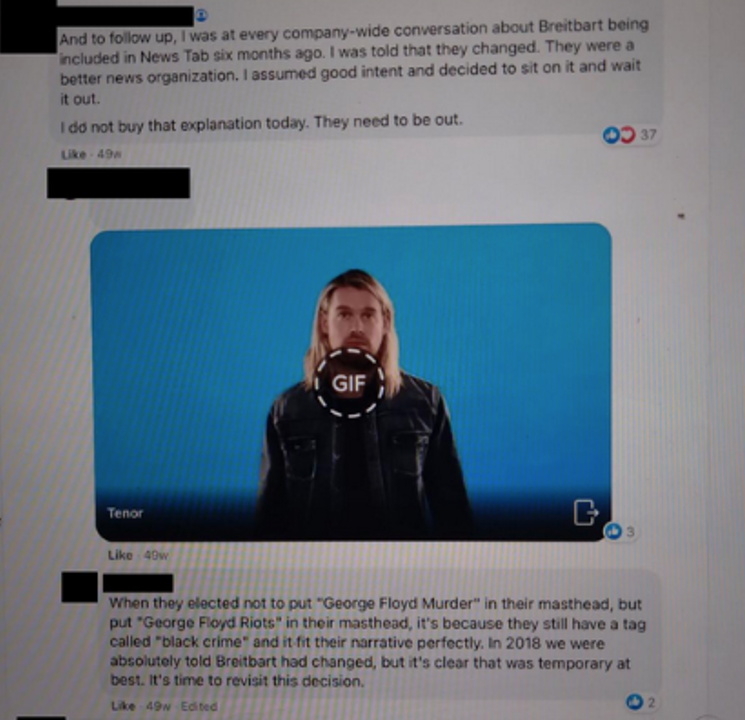
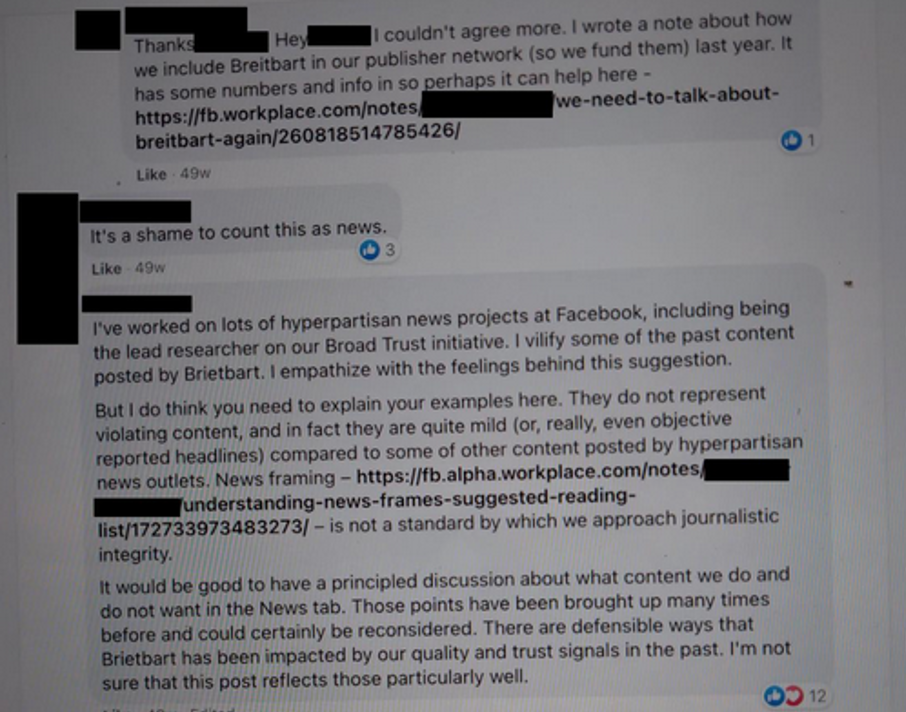
In September 2021, the Wall Street Journal began publishing a series of articles exposing the inner workings of Facebook and subsidiaries such as Instagram, including evidence that company insiders knew Instagram made teen girls’ body image issues worse and that Facebook leaders did little to curb recruitment activities of human traffickers and drug cartels.
Much of that reporting was based on a trove of documents and images leaked by former Facebook product manager Frances Haugen, who came forward publicly several weeks after the series published.
(In October 2021, Facebook Inc., the parent company, was rebranded as Meta Platforms Inc., an effort at least six months in the making that some commentators in the news media noted might have had the effect of blunting public backlash following Haugen’s leaks.)
In November 2021, Harvard Kennedy School’s Public Interest Tech Lab received an anonymous drop of information from the Haugen leak, comprising roughly 20,000 images and more than 800 internal Facebook documents, such as chat threads and research, starting from 2016.
As of October 18, 2023, that information is available to the public, in a searchable format, via a virtual tool called FBarchive. Users need to register for a free account to access the archive.
FBarchive is designed to help researchers, journalists and policymakers understand how, why and when decisions have been made at some of the most influential social media platforms in the world. The project is led by Latanya Sweeney, a technology professor at Harvard who heads the Public Interest Tech Lab.
Sweeney says making these internal deliberations and thought processes public will help policymakers and technology researchers discover solutions to the problem of moderating content on social media platforms that billions of people use.
“We just don’t know how to do moderation at scale — we don’t have the technology, we don’t have the know-how — and that’s something that’s true on all of these platforms where we try to do moderation,” says Sweeney, a pioneer in the field of data privacy. “So, the question is, how should we do that? Can we look at these documents to see where the fault lines are and inspire new technologies, or new technological approaches?”
How to use FBarchive
Go to fbarchive.org and hit “Enter.” This will bring you to a sign-in page. First-time visitors will receive directions to sign up for a new account via the Public Interest Tech Lab’s MyDataCan platform. Harvard-affiliated users can sign in with their university ID. All other users can click “sign up” to create a username and password.
The primary gateway to accessing the FBarchive materials is a Boolean search bar, meaning certain operators, such as “and,” “or” or “not” will either broaden or restrict results. Anyone who wants to view a document in FBarchive needs to be logged in.
The search bar is useful for researchers and reporters who already have some focus on what they are interested in — for example, specific keywords or phrases related to body image, gender issues or global conflicts. Journalists and researchers can also get a general sense of what is in the archive by using broader terms — “drug cartels” or “human trafficking,” for example.
Users can also search for information about particular people, such as executives at Meta. The FBarchive team redacted names of people who likely have an expectation of privacy — a software engineer outside of top management, for example. Names of public figures, such as C-suite executives, politicians and celebrities, are not redacted.
To help users understand what they’re reading, Sweeney and her team created a glossary of terms and phrases found in the documents. The “audience problem,” for example, is “a term used internally to describe the years-long trend of declining post numbers on Facebook,” according to the glossary.
“There’s a lot of inside Facebook language in there,” Sweeney says.

Users can bookmark particular documents and images, and create their own tags, which can be used to curate collections of images and documents. For example, a journalist reporting on how social media affects body image could collect relevant images and documents by adding a “bodyimage” tag to them.

FBarchive story ideas and research angles
The FBarchive is full of unexplored investigative story ideas and scholarly research topics. To get you started, Sweeney has offered questions needing more journalistic and academic attention, including the following, among others:
- Is viral content more likely to increase Facebook’s revenues? How does Facebook handle this tension? Under what circumstances are the needs of human users traded for corporate revenue?
- At least 95 countries are identified in the Facebook documents. What are the top concerns Facebook considers for people in these countries on the platform? Are the concerns and the way Facebook addresses them similar or different across countries?
- Violence and political unrest exists around the world and is evidenced within the Facebook documents. What is the nature and extent that Facebook itself plays in the proliferation of these tensions, if any? What role could Facebook play to help reduce these tensions?
Informing future regulation
The stories and studies prompted by the archive, along with the content of the archive itself, could inform potential regulation.
For legislators and officials interested in regulating tech, trying to understand how Facebook functions has, so far, been like trying to see what’s going on in a “black box,” Sweeney says.
She likens FBarchive to taking an opaque case off an overheating radio and replacing it with a clear one. Everyone can now see the hot spots inside causing problems.
“I just don’t think policymakers have ever had the opportunity to understand where real leverage points were,” Sweeney says. “They always had to depend on what the tech companies themselves said was possible, not possible. And seeing the inside content gives you a much better sense of, how does this really operate?”
Expert Commentary